




호모 사피엔스는 직병렬 구조에 익숙하다
1970년대 서울역 귀성 기차 구매 장면 사진은 과거 어려운 시절 추억의 한 모습이다. 사진 속을 보면 시민들이 서울역 광장을 꽉 메우고 여러 개의 줄로 쭉 늘어 서서 있다.

거기에는 고향의 부모, 형제, 친구들의 모습이 겹쳐져 있다. 서울역 역사 방면에는 매표구가 여러 개가 있게 되고 그 숫자만큼 시민들의 줄이 쭉 병렬로 늘어져 있다.
그러면서 고향의 부모님 뵙고 싶은 마음에 밤을 새워 기다렸을 것이다. 각 열차 구매 행렬은 쭉 늘어선 직렬 종대 행렬로 이루어져 있고, 그 줄이 다시 여러 개의 병렬 줄로 늘어 선다.
이처럼 우리는 생활 속에서 일의 순서를 효과적으로 처리하기 위해서는 순서를 지키는 ‘직렬’ 줄과, 그 일의 처리 속도를 높이는 ‘병렬’ 줄이 같이 존재한다.
질서를 지키기 위해 줄을 잘 서는 것도 국가와 사회의 평가 잣대가 된다.

전기 부품의 구성과 연결 상태를 회로 모델 심볼로 도식화한 것이 전기 회로도 이다. 이러한 전기 회로도에는 전기 부품이 직렬과 병렬 연결의 조합으로 이루어져 있다. 예를 들어 저항, 모터, 전등, 스위치 등과 같은 부품이 쭉 직렬(Serial)로 연결되어 있으면 거기서 소모되는 전압을 모두 더해서 총합하면 그 전압 크기만큼을 외부 배터리나 전원 장치에서 공급해야 한다. 이때 모든 부품에 흐르는 전류는 같고 전압의 합은 외부 배터리 전압과 일치한다. 이 법칙을 회로의 전압법칙(Kirchhoff’s Voltage Law)라고 한다. 모든 부품에 일정 전류를 공급할 때 직렬 연결 방식을 선택한다.
반면에 전기 부품을 병렬(Parallel)로 연결하면 모든 부품에 일정한 전압이 걸리고, 각 부품에 흐르는 전류의 총합이 외부에서 공급하는 전류의 양이 된다. 이 법칙을 회로의 전류법칙(Kirchhoff’s Current Law)라고 한다. 이처럼 회로에서 일정한 전류를 흘리는 직렬 연결의 장점과 일정한 전압을 거는 병렬 연결의 장점에 따라 직렬 회로와 병렬회로를 선택한다.
하지만 전체 전기 회로의 구성은 직렬과 병렬회로의 조합으로 이루어 진다. 보통 신호를 처리하는 전자회로도 마찬가지이고, 신호를 주고 받기 위한 통신 회로도 마찬가지이다. 4차 산업혁명의 핵심 부품인 반도체 메모리 내부의 회로도 그렇고 프로세서 반도체 내부 회로도 마찬가지이다.
인공지능이 소설 쓰고 영화 만드는 시대 온다
과거 서울역 광장의 귀성객 모습과 전기회로의 경우와 마찬가지로 고성능 인공지능 딥러닝 네트워크도 단위 딥러닝(DNN) 구조의 직병렬(Serial-Parallel) 조합으로 구성된다.
필자가 정의하는 대표적인 직렬형 인공지능 네트워크가 CNN(Convolution Neural Network)이다. CNN은 공지능으로 영상을 인식하는데 탁월한 성능을 나타낸다. 사진을 입력하면 한 단계씩 뉴런 층(Layer)을 지나면서 점차 영상 해석 결과가 구체화하고, 추상화되면서 최종적으로 대상을 인식하고 지표(Tag)를 붙인다. 이처럼 CNN 인공지능에서는 뉴런 층이 순서대로 연결되고 신호가 전파한다.
그런데 언어 인식에 주로 쓰이는 순환신경망(Recurrent Neural Network)은 병렬형 (Parallel) 인공지능 망으로 구분할 수 있다. 언어의 경우 주어, 목적어, 동사 등 순서가 정해져 있다. 우리가 “What is your name?” 하고 묻는다면 질문의 단어 자체가 ‘What’, ‘is’, ‘your’, ‘name’ 으로 시간적으로 순차적으로 등장한다. 따라서 한 단어 한 단어 등장할 때 마다 순서대로 기다리면서 병렬적으로 연결된 신경망이 동작한다. 그리고 한 신경망의 해석과 판독 결과가 그 다음 신경망으로 전달된다. 그래서 시간적으로 순차적으로 동작하는 대표적인 병렬형 신경망이 RNN이 된다.
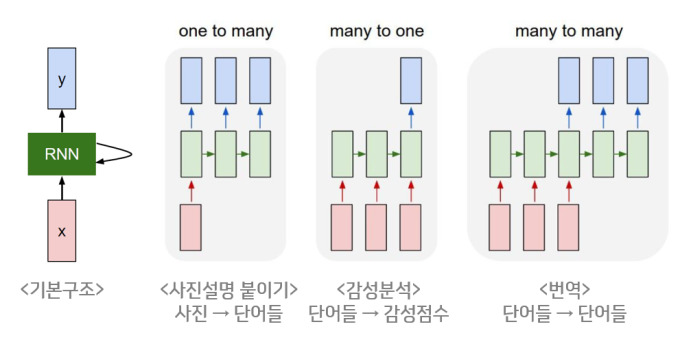
이러한 병렬형 인공지능인 RNN에서 하나의 입력에 대해서 여러 개의 출력(one-to-many)을 낼 수도 있다. 각 출력은 각각 CNN이나 DNN이 만들어 낸다. 이러한 경우 하나의 사진 이미지 입력에 대해서 사진의 제목을 출력을 내놓는 이미지 캡셔닝(Image Captioning) 작업에 사용할 수 있다. 사진의 제목은 단어들의 나열이므로, 여러 개의 병렬 출력이다.
또한 RNN에서 다수의 입력에 대해서 하나의 출력(many-to-one)을 만들 수도 있다. 이 경우 입력 문장으로부터 긍정적 감성인지 부정적 감성인지를 판별하는 감성 분류(Sentiment Classification) 모델에 사용할 수 있다. 그리고 복수입력- 복수출력(many-to-many)의 모델의 경우에는 입력 문장으로부터 대답을 문장으로 출력하는 챗봇의 경우이다. 또한 입력 문장으로부터 번역된 문장을 출력하는 번역기에 사용할 수 있다.
이러한 CNN, RNN의 직병렬 조합된 복합 인공지능은 스스로 영화를 감상할 수 있다. 그러면 한 장면 한 장면을 파악하고 판단하는 인공지능은 직렬형 CNN 인공지능이 담당한다. 그런데 1초에 60장씩 계속 장면이 순서대로 바뀌어 가는 것을 이해하고 예측하는 것은 RNN과 같은 병렬형 인공지능이 담당하게 된다. 이 인공지능은 영화의 내용과 의미를 파악하고 다음 장면을 예측할 수 있다. 이 복합 인공지능은 영화를 보면서 눈물을 흘릴 수 있고, 웃을 수도 있다.
이처럼 미래 인공지능 네트워크도 다양한 기능을 가진 각 인공지능 망의 직병렬 조합으로 이루어지게 된다. 이렇게 되면 인공지능이 영화를 보면서 텍스트를 자동으로 붙이게 될 수 있고, 그 영화를 감상하게 된다. 그 결과를 기사로도 쓸 수 있게 된다. 여기에 변증법적 인공지능인 GAN(Generative Adversarial Network)을 결합하면 인공지능이 영화나 소설도 직접 쓸 수 있다.
인공지능이 스스로를 복제한다면?
이처럼 미래 인공지능은 영상, 음성, 언어, 이해와 창작 기능을 바탕으로 더 나아가 소설, 영화 등 복합적 매체 내용을 이해하고, 설명하고, 예측하는 기능을 갖는 방향으로 진화해 갈 것이다. 그리고 창작도 할 수 있게 된다. 더 나아가 예술과 역사 등 인문학도 감상하게 된다. 상황을 파악하고 이해하는 능력도 갖게 되고, 인간처럼 눈치도 갖게 된다. 더 나아가 인간과 같은 창조와 모방의 기능을 갖게 된다. 그러려면 지금까지 개발된 다양한 인공지능 알고리즘이 복합되어 섞이게 된다.
지금까지 인공지능은 학습 데이터를 이용해서 발전했다. 그래서 빅데이터가 중요했다. 따라서 학습 데이터의 선택에 따라 인공지능도 도덕, 이념, 종교도 갖게 된다. 하지만 더 먼 미래에는 데이터가 없어도 스스로 학습하는 비지도 학습 기능을 갖게 된다. 컴퓨터 스스로 데이터를 생산하고 학습하게 된다. 현재 대표적인 비지도 인공지능이 강화학습(Reinforcement Learning)방법이다.
또한 인공지능 자체의 알고리즘도 일정 부분 인공지능 스스로 개발하는 시대가 언젠가는 올 것으로 본다. 그러면 스스로 인공지능이 자신을 개선하고 진화하고 복제하고, 생산한다. 이러한 시대가 되면 인공지능 보유 여부가 인간 사이에 불평등을 만들 수 있다. 더 나아가 ‘인공지능’과 ‘인간’ 사이에 불평등이 올 수 있다.
하지만 이러한 인공지능이 발전하는 데는 더 빠른 컴퓨터, 더 빠른 메모리 반도체가 필요하다. 더 나아가 전력소모를 지금 보다 극단적으로 줄여야 한다. ‘인공지능 천하’ 시대의 도래 여부는 반도체 기술의 성능 발전 여부와 전력 소모를 줄이는 기술에 구현에 달려 있다. 인간이 ‘반도체’ 주권과 ‘전기 공급’ 주권을 놓지 말아야 한다.
joungho@kaist.ac.kr
[김정호 카이스트 전기 및 전자공학과 교수]

















