




8월 '131억개 모델' 출시...11월에는 '410억개 모델'도 공개
[서울=뉴스핌] 양태훈 기자 = 코난테크놀로지가 17일, 자체 개발한 대규모 언어모델 '코난(Konan) LLM'을 공개했다. 타깃 시장은 B2B·B2G로, 출시 효과는 내년부터 본격적으로 나타날 전망이다.
임완택 코난테크놀로지 전략기획본부장(상무)은 이날 콘래드 서울 호텔에서 열린 기자간담회에서 "코난 LLM은 성능, 비용, 보안을 모두 다 잡은 국내 최초의 B2B, B2G향 LLM"이라며, "SI(System Integration), 파인튜닝, B2B, B2G 고객사를 대상으로 온프레미스로 제공할 계획"이라고 전했다.
또 "라이선스 또는 연간 구독 판매를 통한 수익을 기대한다"며, "올해 코난 LLM을 기반으로 회사 (매출이) 크게 도약할 것으로 기대하고 있다"고 덧붙였다.

코난 LLM은 파라미터 크기에 따라 131억개(13.1B) 모델과 410억개(41B) 모델로 구성됐다. 131억개 모델은 이달 중 출시되며, 410억개 모델은 올해 11월에 공개될 예정이다.
학습 토큰은 131억개 모델은 4920억개(한국어 2840억개), 410억개 모델은 7000억개(한국어 3220억개)가 사용됐다. 언어모델이 문장을 생성할 때 필요한 토큰의 수를 나타내는 Context length는 131억개 모델이 2K, 41억개 모델이 4K(4000자)에 달한다.
파라미터 사이즈는 오픈AI의 'GPT-3.5(파라미터 1750억개)', 네이버의 '하이퍼클로바(파라미터 2040억개)'보다 적지만, 전체 토큰 및 한국어 토큰은 더 많아 뛰어난 가성비를 갖췄다는 게 회사의 설명이다.
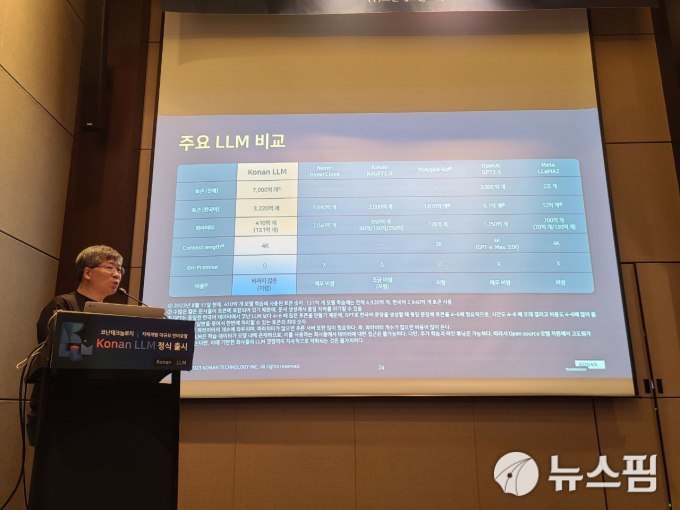
임완택 상무는 "LLM(Large Language Model·대규모 언어 모델)의 성능은 파라미터가 클수록 좋지만, 그만큼 추론 서버가 필요해 학습 비용이 많이 들어가고, 비용 이슈가 발생할 수밖에 없다"며, "코난테크놀로지는 적절한 비용으로 B2B·B2G 고객들에게 딱 맞는 최고의 성능을 제공하기 위해 파라미터 크기는 줄이되 학습 토큰을 늘렸다"고 설명했다.
이어 "코난 LLM은 문서 초안 생성, 문서 요약, 질의 응답 생성에 특화됐으며, 8월 현재 410억개 모델에 대한 학습을 시작했다"며, "410억개 모델은 문서 작성 및 요약을 위한 파인튜닝을 거쳐 출시될 예정"이라고 덧붙였다.

다음은 이날 행사 이후 진행된 Q&A 세션을 정리한 내용이다.
▲ SK텔레콤과 전략적으로 협업하고 있는데, SK텔레콤의 서비스에 코난 LLM이 도입될 가능성도 있나?
- SK텔레콤의 서비스는 '에이닷'이라는 B2C 서비스이고, 코난 LLM은 B2B에 특화된 서비스다. 지난해 SK텔레콤과 인공지능(AI) 관련 전략적 업무협약을 체결한 바 있다. (현재) 성과를 내기 위해 지속적으로 이야기하고 있다.
▲ B2B, B2G 공급 계획이 궁금하다.
- 코난 LLM에 대한 기업들(삼성전자 등)과 기관들의 관심이 많다. 오늘도 파트너스 데이를 진행한다. 대기업 및 공공기관에서 60여 명이 참석할 예정이다.
▲ 온프레미스 방식의 한계는 없나?
- (클라우드와 비교해) 온프레미스의 제약은 없다고 생각한다. 130억개 모델의 경우, 엔비디아의 RTX 3090에서도 구동할 수 있을 정도로 최소 사양이 낮다.
▲ 국내 시장에서만 제품(코난 LLM)을 제공할 계획인가?
- 당분간은 국내 시장에만 집중할 계획이다.
dconnect@newspim.com

















