글로벌 빅테크와 경쟁 본격화…생성형 AI 춘추전국시대
"자체기술 탑재 후 환각 현상 72% 감소"
[서울=뉴스핌] 배요한 기자 = 네이버가 3년 동안 1조원을 투자해 개발한 초거대 인공지능(AI) 모델 '하이퍼클로바X'가 베일을 벗었다. 마이크로소프트, 구글 등 글로벌 빅테크들과의 AI 경쟁도 본격화 됐다.
25일 업계에 따르면 전날 네이버는 팀네이버 컨퍼런스 '단 23'을 개최하고 초대규모 AI '하이퍼클로바'를 개발한 이후 2년 만에 업그레이드 모델 '하이퍼클로바X'를 공개했다.
이날 컨퍼런스에서 네이버는 하이퍼클로바X를 적용한 세 가지의 서비스를 소개했다. 대화형 AI 서비스인 '클로바X(CLOVA X)', 기업 생산성 향상을 위한 AI 플랫폼 '프로젝트 커넥트X(Project CONNECT X)' 그리고 비즈니스에 최적화된 AI 개발도구 '클로바 스튜디오(CLOVA Studio)'다.
네이버 관계자는 "20년 이상 축적된 데이터 자산을 활용해 한국 최적의 생성형 AI 모델을 구현했다"며 "기존 사업인 검색, 커머스, 광고, 클라우드, 웹툰 등 콘텐츠 사업 전반에 적용함으로써 소비자와 셀러, 개발자, 기업 모두의 편의성 및 업무효율성을 향상시킬 수 있다"고 밝혔다.

◆ 글로벌 초대형 빅테크와 경쟁 본격화..."챗GPT 대결 승률 75%"
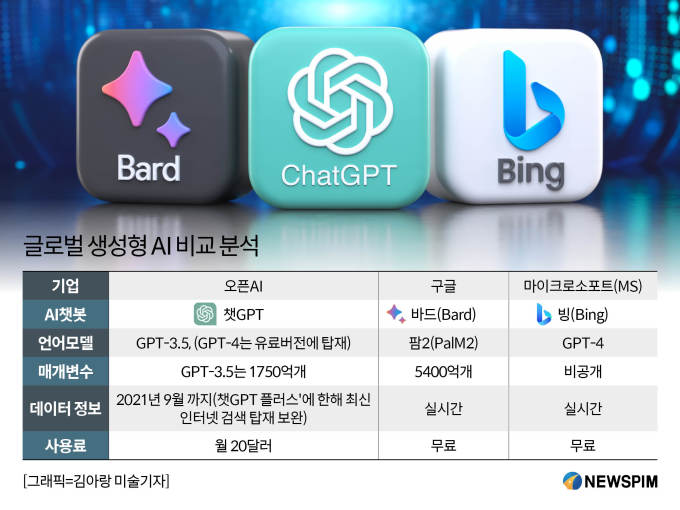
네이버가 초거대AI 모델 하이퍼클로바X를 공식 발표하면서 오픈 AI의 '챗GPT'으로 시작된 '생성형 AI' 시장은 그야말로 춘추전국시대가 열리게 됐다. 현재 오픈AI의 'GPT', 구글의 '팜2', 마이크로소프트(MS)의 'GPT-4' 등 해외 빅테크들의 거대 언어 모델(LLM)이 시장을 선도하고 있는 가운데 네이버가 이들에 맞서 경쟁력을 입증할 수 있을지 관심이 쏠린다.
네이버는 이번에 출시한 '하이퍼클로바X의 파라미터(parameter, 매개변수)를 공개하지 않았다. 매개변수는 입력된 데이터에서 원하는 출력값을 얻기 위해 AI가 찾아내야 하는 변수로, 통상 이 수치가 높으면 우수한 AI모델이라고 평가받는다.
다만 이전 모델인 하이퍼클로바의 성능지표로 하이퍼클로바X의 성능을 가늠해볼 수 있다. 지난 2021년 네이버가 공개한 하이퍼클로바의 매개변수는 2040억개다. 반면 오픈AI가 개발한 초거대 AI 'GPT-3.5'의 매개변수는 1750억개로 하이퍼클로바X보다 낮다 수준이다.
단순 수치상으로 비교해볼 때 네이버의 하이퍼클로바X는 챗GPT에 적용된 초거대AI보다 성능 면에서 우위에 있다고 볼 수 있는 셈이다.
성낙호 네이버클라우드 하이퍼스케일 AI 기술 총괄은 "초거대 규모의 언어모델의 성능을 어떤 하나의 수치로 비교하는 것은 어렵다"라면서도 "내부적으로 우리 모델과 GPT-3.5의 시뮬레이션을 진행해본 결과 75%의 높은 승률을 기록했다"고 말했다.
생성형 AI의 문제점으로 지적돼온 '환각(hallucination) 현상'에 대해서도 좋은 평가를 받았다. 대표적 대화형 AI 서비스인 챗GPT는 환각현상이 빈번하게 나타나 정확도가 중요한 검색 서비스에 부적절하다는 논란이 있었다. 반면 하이퍼클로바X는 내부 테스트 결과, 자체기술 탑재 후 환각 현상이 72% 감소한 것으로 알려졌다. '환각 현상'은 생성형 인공지능 서비스가 사실이 아닌 것을 사실처럼 말하는 현상이다.
네이버는 오는 11월 단일 기업으로는 아시아 최대 규모인 60만 유닛 이상의 서버를 수용할 수 있는 하이퍼스케일 데이터센터 '각 세종'을 오픈할 예정이다. '각 세종'은 초대규모AI의 브레인센터 역할을 수행하게 된다.
 |
◆ '국내용' 우려...저작권 논란 '불씨'
네이버에 따르면 하이퍼클로바는 GPT-3보다 한국어 데이터를 약 6500배 이상 학습한 것으로 알려졌다. 한국어 데이터 학습 기반을 통해 영어 형식의 챗 GPT보다 자연스럽고 이해하기 쉬운 한국어로 답변을 해줄 수 있다는 평가가 나온다.
하이퍼클로바X가 영어 중심의 오픈AI '챗GPT'나 구글의 '바드'와 달리, 한국 시장에서 유리한 고지를 선점한 것은 분명하지만, '국내용'이라는 우려의 목소리도 적지 않다. 실제 네이버는 컨퍼런스에서 구체적인 해외 진출 계획을 공개하지 않았다.
최수연 네이버 대표는 해외 시장 진출을 묻는 질문에 "하이버클로바X가 영어·일본어 등 여러 외국어도 굉장히 잘한다"면서도 "이길 수 있는 시장을 먼저 잡기 위해 한국 타깃의 국내 스타트업 수요를 맞춘 것으로, 글로벌 진출 요구에도 대응하겠다"며 모호한 답변을 내놨다.
성낙호 네이버 총괄은 "유니버셜하게 전체에 대한 데이터를 학습한다면 그걸 똑같은 성능을 발휘하는 인공지능을 만드는 과정에서 훨씬 더 고비용 구조를 가질 수밖에 없다"라며 "우리는 생성형 AI에서도 로컬라이즈된 사업 전략이 필요하다고 생각했고, 한국 시장에 특화된 모델을 만들고 경량화를 진행하고 있다"고 설명했다.
이제 막 개화하는 글로벌 생성형 AI 시장 전망은 굉장히 밝은 편이다. 스탠더드앤드푸어스(S&P) 글로벌 마케팅 인텔리전스가 조사한 전세계 생성형 AI 시장 규모는 올해 37억360만 달러(약 4조 9,606억원) 규모로 연평균 58% 성장해 2028년에는 10배 이상 성장할 것으로 예상했다. 그랜드 뷰 리서치는 Chat GPT 등 생성형 AI에서 비롯된 데이터 서비스 및 솔루션 수요가 2022년 글로벌 시장에서 약 90억 달러(약 11조 9502억원)를 기록했으며, 2030년에는 660억 달러(약 87조 6348억원) 규모로 급성장할 것으로 추정했다.
국내 생성형 AI 시장에 대한 구체적인 자료는 없지만, 국내 AI기업 매출액은 2020년 1조 9506억원에서 지난해 3조 9702억원으로 2배 이상 증가한 것으로 나타났다. 국내 AI 시장 규모가 증가 추세를 보이는 것은 확실하지만 글로벌 시장과 비교해서는 상당한 차이가 나는 셈이다.
네이버는 초거대AI 하이퍼클로바X를 개발하는데 3년동안 1조원 가량을 쏟아 부었다. 앞으로 기술 고도화에 따른 개발 비용으로 천문학적인 추가 비용이 투입될 수 있는 상황에서 해외 시장 점유율 확보는 필수적이다.
네이버가 풀어야할 숙제로 저작권 문제도 남아있다. 앞서 네이버는 보유한 50년치 뉴스와 9년치 블로그 데이터가 생성형AI 학습에 사용됐다며 저작권 논란에 휩싸였다.
최근 한국신문협회는 '생성형 인공지능(AI)의 뉴스 저작권 침해 방지를 위한 신문협회 입장'을 내고 "정당한 권한과 근거 없이 뉴스 콘텐츠를 AI 학습에 이용하는 것은 언론사가 뉴스 콘텐츠에 대해 갖는 저작권 및 데이터베이스(DB) 제작자로서의 권리를 침해하는 것"이라고 입장을 표명한 바 있다.
이와 관련해 최수연 대표는 "하이퍼클로바를 출시할 때 그 학습한 데이터의 규모를 알기 쉽게 전달하는 과정에서 '뉴스 50년치'가 아니고, 1년에 검색되는 뉴스 분량의 50배 혹은 블로그에 몇 배다 이런 식으로 비교해서 언급했는데 그 부분에서 오해가 있었던 것 같다"고 저작권 침해 사실을 부인했다.

yohan@newspim.com